 I'MTech L'actualité scientifique et technologique de l'IMT
I'MTech L'actualité scientifique et technologique de l'IMT
Victor Charpenay, Mines Saint-Étienne – Institut Mines-Télécom, chercheur au LIMOS (UMR CNRS 6158)
YouTube, comme la plupart des plates-formes numériques mondiales, est un « serveur-sirène ». Elle est en effet capable de capter notre attention et de la conserver, jalousement, au point de ne plus naviguer nulle part ailleurs sur le web. Ce qui nous retient sur YouTube, c’est principalement son algorithme de recommandation : en 2018, 70 % des vidéos que nous voyions étaient des recommandations. Pour chaque vidéo visionnée, l’algorithme en recommande d’autres et, immanquablement, les vidéos s’enchaînent sans que l’on s’en aperçoive.Comment fonctionne l’algorithme de recommandation de YouTube ? Imaginons que YouTube (donc Google) ne me connaisse pas encore car j’accède à la plate-forme sans être identifié, depuis un lieu inconnu du cyberespace français (possible avec un VPN, par exemple).
Je vois depuis la page d’accueil des vidéos récentes et les « tendances » du moment. Une des tendances en France semble être la chanson “Kobe (feat. Zola)”, du groupe 13 Block. Je clique.
C’est un morceau de rap – YouTube ne me connaît effectivement pas – et sans information préalable, une liste de recommandations s’affiche déjà à la suite de la vidéo. On y trouve avant tout d’autres morceaux du groupe (issus du même album, sorti quelques jours plus tôt). Logique. Pourtant, déjà, on peut constater l’étendue de la « connaissance » de l’algorithme, qui n’aura pu produire ces recommandations que s’il a eu accès à une base de données de disques régulièrement mise à jour. Et en effet, Google possède le plus gros catalogue musical au monde, devant ceux de Spotify et Deezer. Ce sont les labels eux-mêmes qui alimentent ce catalogue, motivés par les droits d’auteur·e qui vont avec (le descriptif de la vidéo indique « Provided to YouTube by Elektra France », le label de 13 Block).
Grâce à son catalogue fourni, l’algorithme de recommandation de YouTube peut proposer d’autres artistes que 13 Block. La liste de vidéos recommandées inclut par exemple Vald, un autre rappeur qui sortait un morceau dans la même période intitulé GOTAGA.
Encore une fois, c’est logique : 13 Block et Vald font tous les deux du rap. Mais comment l’algorithme le sait-il ? Le descriptif des deux vidéos donne un label, un producteur, un réalisateur mais pas de genre. Il existe bien des algorithmes avancés d’apprentissage automatisé pour reconnaître un genre à partir de l’enregistrement audio… mais il y a plus simple : Wikipedia.
En effet, les fiches Wikipedia respectives des deux artistes ont le tableau récapitulatif suivant (appelé « infobox » sur Wikipedia) :

Fiches Wikipedia de 13 Block et Vald.
Source, Author provided
À partir de ces informations, l’algorithme peut établir que 13 Block et Vald sont deux artistes français stylistiquement proches : « rap hardcore » apparaît sur les deux fiches. L’algorithme peut même arriver à saisir, malgré les subtilités du genre, que la « trap » et le « horrorcore » sont deux sous-genres du rap qui rapprochent encore les deux artistes. En lisant la fiche dédiée au rap hardcore, on lit en effet que le hardcore trouve ses origines culturelles dans le hip-hop et que la trap et le horrorcore en sont des genres dérivés, tout comme le « gangsta rap ». Sur la fiche « hip-hop », on trouve d’autres sous-genres, comme le « hip-hop chrétien » (sûrement assez distinct de son homologue gangsta).
En proposant d’écouter Vald après 13 Block, YouTube met en avant des relations qui n’apparaissent sur Wikipedia que lorsque l’on navigue de fiche en fiche, comme on navigue sur le web. Ce type de navigation a donné naissance à une structure particulière en informatique : le « graphe de connaissance » (« Knowledge Graph », en anglais). Voici un aperçu de graphe de connaissance extrait de Wikipedia :
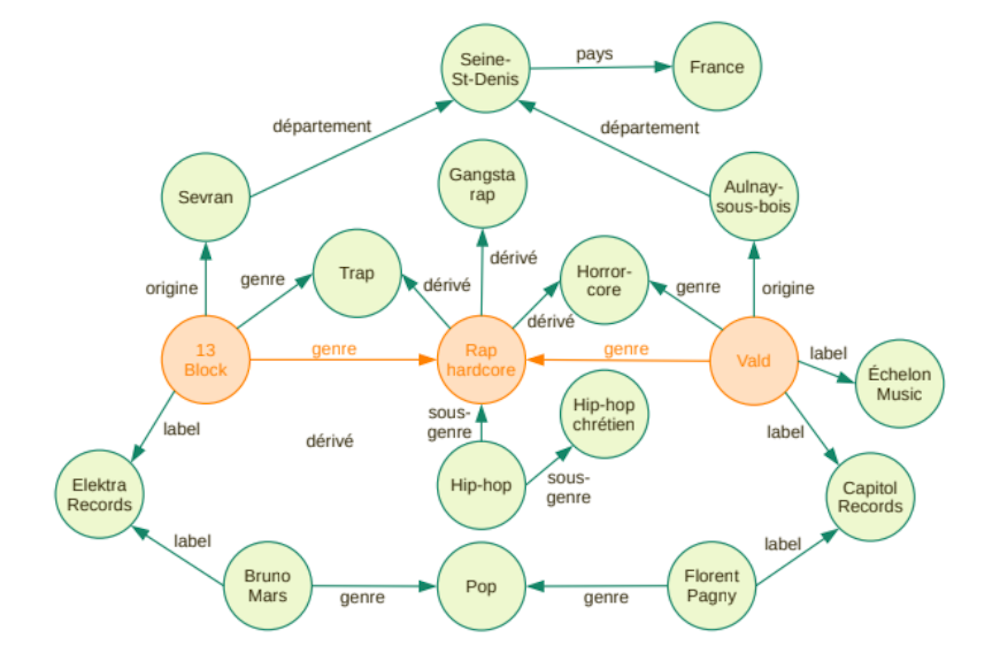
Exemple de graphe de connaissance.
Source, Author provided
À l’aide de ce réseau de concepts reliés entre eux par des relations dites « sémantiques », l’algorithme de YouTube peut passer d’une œuvre à l’autre en parcourant les concepts voisins. Parcourir des concepts dans un graphe s’apparente alors à la pensée humaine, notamment les associations d’idées que l’on pourrait faire en tant qu’humain. C’est du moins l’hypothèse qui est faite dans la conception d’un graphe de connaissance. On peut donc naviguer par genre, par titre, par label, par discographie ; autant de manières de concevoir une liste de lecture sans fin, qu’exploite subtilement la sirène YouTube. Le graphe de connaissance ci-dessus révèle même des relations indirectes entre concepts. 13 Block et Vald sont par exemple tous deux originaires de Seine-Saint-Denis (comme beaucoup de rappeurs français).
L’idée d’utiliser des graphes de connaissance pour structurer l’information n’est pas nouvelle mais c’est Google qui lui donne ce nom, en 2012, pour une campagne de communication autour de son nouveau produit : « the Knowledge Graph », qui est une base de données centrées sur les concepts décrits dans Wikipedia. Le Knowledge Graph de Google avait été précédé de projets académiques pionniers ((Yet Another Great Ontology et DBpedia) et il sera suivi par d’autres graphes de connaissance « industriels », construits par de grandes entreprises du numérique (entre autres, Facebook, Microsoft, IBM et eBay). La fondation Wikimedia, qui assure l’accès à Wikipedia, a elle aussi lancé récemment son graphe de connaissance collaboratif : Wikidata.
Wikidata incorpore (encore partiellement) les données structurées de Wikipedia. Pourquoi alors copier-coller ces données d’un wiki à l’autre ? Si l’opération est intéressante sur plusieurs points, elle a un avantage technique considérable. En passant d’infobox sous forme de tableaux à un graphe unifié, accéder à son contenu de manière automatisée est plus efficace. Lorsque l’algorithme de YouTube cherche les praticien·ne·s du « rap hardcore » autres que 13 Block, il peut le faire en un saut, du concept « rap hardcore » à ses voisins selon la relation « genre ». C’est beaucoup plus rapide que de parcourir les infobox de toutes les fiches Wikipedia une à une. Sur Wikidata, accéder aux 399 artistes de rap hardcore prend 750 ms. Des requêtes plus complexes prennent à peine plus de temps. Vérifier, par exemple, que les habitant·e·s de Seine-Saint-Denis sont légèrement surreprésentés dans le rap français, prend 1,1 s : selon Wikidata, les Séquano-Dionysien·ne·s représentent effectivement 6,9 % du rap français pour seulement 2,4 % de la population française.
Accéder à Wikidata de manière automatisée et l’intégrer dans des applications tierces est fortement encouragé par la fondation Wikimedia. À l’inverse, utiliser le Knowledge Graph de Google est strictement réservé à ses ingénieur·e·s. Le seul indice que laisse Google sur le contenu de son graphe de connaissance est l’encart qui apparaît, à côté de la liste des résultats, lorsque l’on cherche « 13 Block », « Vald » ou « rap hardcore » sur Google Search. L’encart qui s’affiche ressemble beaucoup à l’infobox de Wikipedia (qu’il référence d’ailleurs souvent) et est le signe que l’information affichée est extraite du Knowledge Graph de Google et non de pages web.
Ainsi, lorsque des recommandations YouTube peuvent surprendre, il n’est pas facile de reconstruire le cheminement de l’algorithme. C’est le cas avec une recommandation à la suite de « Kobe », la vidéo tendance de 13 Block : pourquoi l’algorithme recommande-t-il « Je vous présente ma copine », une vidéo qui semble n’avoir aucun lien avec le rap ? L’algorithme n’a pas d’historique de visionnage pour personnaliser mes recommandations ; prend-il cependant en compte la seule popularité d’une vidéo comme critère ? L’auteur de la vidéo, Lonni, est un youtubeur très suivi, ce qui rend l’hypothèse plausible. Mais pour un algorithme, faire ce choix est souvent dangereux car il laisse la place à des boucles infinies, de type œuf-poule : la vidéo recommandée est-elle populaire parce que Lonni est « people »… ou l’inverse ?
Lorsque l’on cherche qui est Lonni sur Google Search, pour sonder le Knowledge Graph de Google, on entrevoit une autre piste. Car, avec la liste de résultats s’affiche un encart mentionnant « Lonni – groupe de musique ». Lonni n’est ni sur Wikidata, ni sur Wikipedia. Seul Google semble savoir que le youtubeur est aussi producteur de musique. Dans son graphe de connaissance, 13 Block et Lonni seraient alors voisins, ce qui expliquerait la recommandation faite par YouTube. On peut aussi constater que les thèmes principaux de la chaîne YouTube de Lonni sont la culture manga et le rap. Mais impossible de savoir si Google le sait. L’encart de Google Search n’est pas exhaustif. On remarque au passage que le Knowledge Graph ne semble pas non plus parfait car l’encart mélange les informations de Lonni avec celles d’un homonyme, groupe de punk estonien.
Au-delà de la justification du choix de Lonni, combien d’autres rappeurs français auraient pu apparaître parmi les recommandations ? Wikidata en donne 218 mais beaucoup d’artistes n’ont pas encore été incorporé·e·s dans Wikidata. 13 Block ne l’est pas, par exemple. Il est impossible pour le public de savoir ce que YouTube promeut et ce que la plate-forme cache. La question est pourtant cruciale pour les artistes car de leur visibilité en ligne dépend une grande partie de leur rémunération. Celle des youtubeurs aussi et il serait difficile de justifier la promotion dont bénéficie Lonni-youtubeur par le biais de Lonni-producteur-de-musique. Deux semaines après leur mise en ligne, la vidéo de 13 Block totalise 280k vues et celle de Lonni 580k (Vald, lui, totalise 5,3 millions de vues)…
« Justifier » est d’ailleurs la seule chose que je peux faire à propos de l’algorithme de recommandation de YouTube. Je ne peux pas le décrire dans toute sa complexité mais seulement proposer une justification aux choix particuliers qu’aura fait l’algorithme. Du peu que l’on sait de son fonctionnement, il n’utilise en fait pas explicitement de graphe de connaissance. Il utilise plutôt un réseau de neurones artificiels, qui ne cherche qu’à maximiser aveuglément le temps de visionnage par recommandation. Les termes comme « rap » ou « Seine-Saint-Denis » sont certes « perçus » par le réseau de neurones (comme des suites de lettres) mais ils ne sont pas interprétés comme étant des concepts interconnectés. Si l’algorithme recommande Vald ou Lonni après 13 Block, c’est surtout parce que d’autres utilisateur·trice·s de YouTube avaient navigué de l’un aux autres, partageant la connaissance apprise d’autres sources que tous ces artistes sont aussi rappeurs.
Un graphe de connaissance est donc la représentation structurée d’une connaissance commune (parfois même universelle). C’est parce que cette connaissance est commune que je peux espérer justifier de manière convaincante de « comment fonctionne l’algorithme de recommandation de YouTube » avec un graphe de connaissance. Ce « commun » émerge en grande partie des millions de contributions publiques sur Wikipedia. Lorsque l’algorithme consomme des données qui ne sont pas publiques (parce qu’elles sont, par exemple, fournies par les labels à YouTube plutôt qu’à un organisme public de gestion des droits d’auteur·e), en justifier les choix est difficile sinon impossible. Les graphes de connaissances publics en tant que communs sont pour cette raison un outil essentiel à la compréhension des algorithmes modernes.![]()
Victor Charpenay, Enseignant-chercheur en informatique, Mines Saint-Étienne – Institut Mines-Télécom
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.