 I'MTech L'actualité scientifique et technologique de l'IMT
I'MTech L'actualité scientifique et technologique de l'IMT
Maurizio Filippone, Professeur à EURECOM, Institut Mines-Télécom (IMT)
Nous assistons actuellement à une accélération exponentielle de l’intégration de l’intelligence artificielle (IA) dans notre quotidien, par le biais des algorithmes qui gèrent machines et organisations. Cela pourrait se traduire par divers changements bénéfiques pour nos sociétés : économie, conditions de vie, éducation, bien-être et divertissements.Un tel avenir positif est toutefois rendu problématique en raison d’obstacles liés à la confidentialité, à l’explicabilité des technologies ou à la responsabilité de ses acteurs, pour ne citer qu’eux. Ces questions, qui sont au centre de divers débats dans les médias, constituent une menace pour une adoption sans heurt de l’IA par les citoyens.
Mais le fait que les technologies d’IA telles qu’elles sont conçues aujourd’hui ne sont absolument pas viables est un aspect peut-être encore plus inquiétant. Si nous n’agissons pas rapidement, cela deviendra le principal obstacle à l’intégration généralisée de l’intelligence artificielle dans la société.
Au cœur de l’IA, l’apprentissage automatique
Avant d’examiner ces divers problèmes, définissons ce qu’est l’IA. Cette technologie vise à créer des agents artificiels qui prennent la forme de lignes de code. Ils sont capables de détecter, de décrypter l’environnement et, surtout, d’apprendre en interagissant avec celui-ci. L’apprentissage automatique (machine learning, ou ML, en anglais) est un composant essentiel de l’IA qui permet d’établir des corrélations et des relations de cause à effet entre des variables d’intérêt à partir de données et d’une connaissance préalable des processus caractérisant l’environnement de l’agent.
Par exemple, dans les sciences de la vie, le ML peut être utile pour déterminer la relation entre le volume de matière grise et la progression de la maladie d’Alzheimer. En sciences de l’environnement, il peut estimer l’effet des émissions de CO2 sur le climat. Un aspect clé de certaines techniques de ML, en particulier du système bayésien, est la possibilité de le faire en tenant compte de l’incertitude due au manque de connaissance du système, ou du fait d’une quantité limitée de données disponibles.
Missed it? Faster, more accurate diagnoses: #Healthcare applications of #AI research #PrecisionMedicine #Healthcare #Diagnostics #imaging #digitalhealth https://t.co/mTtGKSiFKw pic.twitter.com/XsU4v4CaSL
— Dr. Thomas Wilckens (@Thomas_Wilckens) April 16, 2019
Prendre en compte une telle incertitude est d’une importance fondamentale dans la prise de décision lorsque le coût associé à différents résultats est déséquilibré. L’IA peut être une aide précieuse dans des domaines comme pour les scénarios médicaux (diagnostic, pronostic, traitement personnalisé…), les sciences de l’environnement (climat, tremblement de terre/tsunami…) et l’élaboration de politiques (trafic, lutte contre les inégalités sociales…).
IA non durable
Les récentes et spectaculaires avancées en matière de ML ont contribué à un regain d’intérêt sans précédent pour l’IA, ce qui a généré d’énormes afflux de financements privés dans ce domaine (Google, Facebook, Amazon, Microsoft, OpenAI). Tout cela encourage la recherche sur le terrain mais sans pour autant tenir compte de son impact sur l’environnement. Or, la consommation d’énergie des appareils informatiques augmente à un rythme effréné. On estime que dans les dix prochaines années, elle comptera pour 60 % de la quantité totale d’énergie produite. Et elle deviendra totalement insoutenable d’ici 2040.
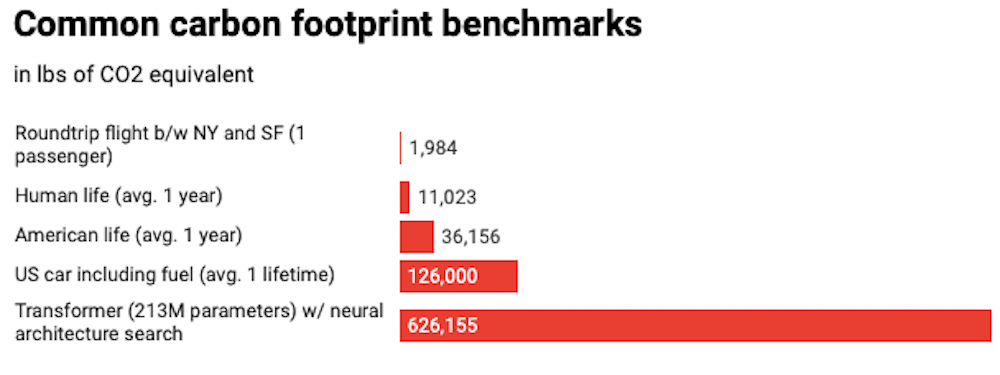
Des études récentes montrent que le secteur des technologies de l’information et de communication (TIC) génère aujourd’hui environ 2 % des émissions mondiales de CO2, soit un niveau comparable à celui de l’industrie aéronautique mondiale. Pis, les prévisions de croissance des émissions des TIC sont réellement alarmantes, et dépassent de loin celle de l’aviation. Le ML et l’IA étant des disciplines en plein essor dans ce domaine, cette perspective est inquiétante. Des études récentes montrent que l’empreinte carbone pour former un modèle ML connu des spécialistes ; appelé auto-encoder, peut polluer dans des proportions allant jusqu’à l’équivalent de celles de cinq voitures tout au long de leur durée de vie.
Si, pour créer de meilleures conditions de vie et améliorer notre estimation du risque, nous avons un tel impact sur l’environnement alors nous sommes voués à l’échec. Que pouvons-nous faire pour que cela change ?
Et la lumière fut
Pour résoudre ce problème, des solutions basées sur le modèle de l’un des principaux composants électroniques, le transistor, commencent à émerger. Google a ainsi développé l’unité de traitement de tenseur (tensor processing unit, ou TPU) et l’a mise à disposition en 2018. Les TPU offrent une consommation d’énergie bien inférieure à celle des deux microprocesseurs GPU (graphics processing unit) et CPU (central processing unit) par unité de calcul. Mais est-il possible de rompre avec la technologie à base de transistors pour des calculs informatiques avec une puissance inférieure et peut-être plus rapide ? La réponse est oui ! Ces dernières années, on a tenté d’exploiter la lumière dans le cadre de calculs rapides à faible consommation. Ces solutions sont quelque peu rigides dans la conception du matériel mais conviennent à des modèles ML spécifiques, tels que les réseaux de neurones.
Il est intéressant de noter que la France est à l’avant-garde dans ce domaine avec le développement d’appareils grâce à des fonds privés et au financement public alloué à la recherche afin de mener à bien cette révolution. La société française LightOn a récemment développé un nouveau dispositif basé sur l’optique qu’ils ont baptisé Optical Processing Unit (OPU).
“L’informatique optique visant la montée en puissance de l’intelligence artificielle”, Igor Carron, PDG de LightOn (CognitionX, 2018).
Les OPU effectuent une opération spécifique, à savoir une transformation linéaire des vecteurs d’entrée suivie d’une transformation non linéaire. Il est intéressant de noter que cela se fait avec un appareil exploitant les propriétés de diffusion de la lumière, de sorte que, dans la pratique, ces calculs ont lieu à la vitesse de la lumière et avec une faible consommation d’énergie.
De plus, il est possible de gérer de très grandes matrices (de l’ordre de millions de lignes et de colonnes), ce qui serait difficile avec les CPU et les GPU. En raison de la diffusion de la lumière, cette transformation linéaire équivaut à une projection aléatoire, par exemple la transformation des données d’entrée par une série de nombres aléatoires dont la distribution peut être caractérisée.
Les projections aléatoires sont-elles utiles ? Étonnamment oui ! Une preuve de concept selon laquelle cela peut être utilisé pour déployer à grande échelle les calculs de certains modèles ML (kernel machines ou méthode dite à noyau qui sont des alternatives aux réseaux de neurones) a été explicité ici. D’autres modèles de ML peuvent également utiliser des projections aléatoires pour prédire ou détecter les points de changement dans une série chronologique.
Nous pensons qu’il s’agit d’une approche très intéressante pour rendre les méthodes de ML modernes évolutives et durables. Cependant, le plus grand défi pour l’avenir consiste à repenser la conception et la mise en œuvre des modèles de ML bayésiens de manière à pouvoir exploiter les calculs fournis par les OPU. Nous commençons à peine à développer la méthodologie nécessaire pour tirer pleinement parti de ces appareils pour le ML bayésien. J’ai récemment reçu une bourse française pour y parvenir.
Il est fascinant de constater à quel point la lumière et le caractère aléatoire sont non seulement omniprésents dans la nature, mais sont également mathématiquement utiles pour effectuer des calculs capables de résoudre de vrais problèmes.

Créé en 2007 pour accélérer et partager les connaissances scientifiques sur les grands enjeux sociétaux, le Fonds de Recherche Axa a soutenu près de 600 projets à travers le monde menés par des chercheurs de 54 pays. Pour en savoir plus, visitez le site du Axa Research Fund.![]()
Maurizio Filippone, Professeur à EURECOM, Institut Mines-Télécom (IMT)
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.
La version originale de cet article a été publiée en anglais.
3 comments
Pingback: Maurizio Filippone - I'MTech
Pingback: Veille Sécurité IA – N75 – Veille Sécurité – Intelligence Artificielle
Pingback: Veille Cyber N248 – 16 septembre 2019 |